Data engineering at Deriv: Building robust infrastructure
.webp)
In today’s data-driven world, have you ever felt overwhelmed by the sheer volume of information or frustrated by the lack of a unified, accessible data infrastructure?
At Deriv, we understand these challenges firsthand. As an online trading company, data is the lifeblood that fuels the company’s success. With a staggering 17 terabytes of data processed daily and over 600 users running hundreds of thousands of SQL queries monthly on analytics dashboards, the data engineering team plays a crucial role in building and maintaining the robust infrastructure that powers Deriv’s data-driven operations.
Just like a bustling city relies on its infrastructure to function smoothly, Deriv’s data engineering team acts as the central hub, connecting various data sources and ensuring the timely delivery of information to the different departments.
This reliance on data extends to the very heart of Deriv’s operations. From analysing customer lifetime value and segmenting our customer base to uncovering long-term trends within our rich historical data, our data empowers us to make informed decisions. In this article, we delve into how our data engineering processes enable us to achieve fast and precise decision-making across the organisation.
Deriv’s data platform architecture
Deriv’s data platform is a well-designed ecosystem that integrates various data sources, including relational databases, APIs, and external files, into a centralised data warehouse. This architecture, visualised in the flowchart, allows for efficient data processing, storage, and consumption across the organisation.
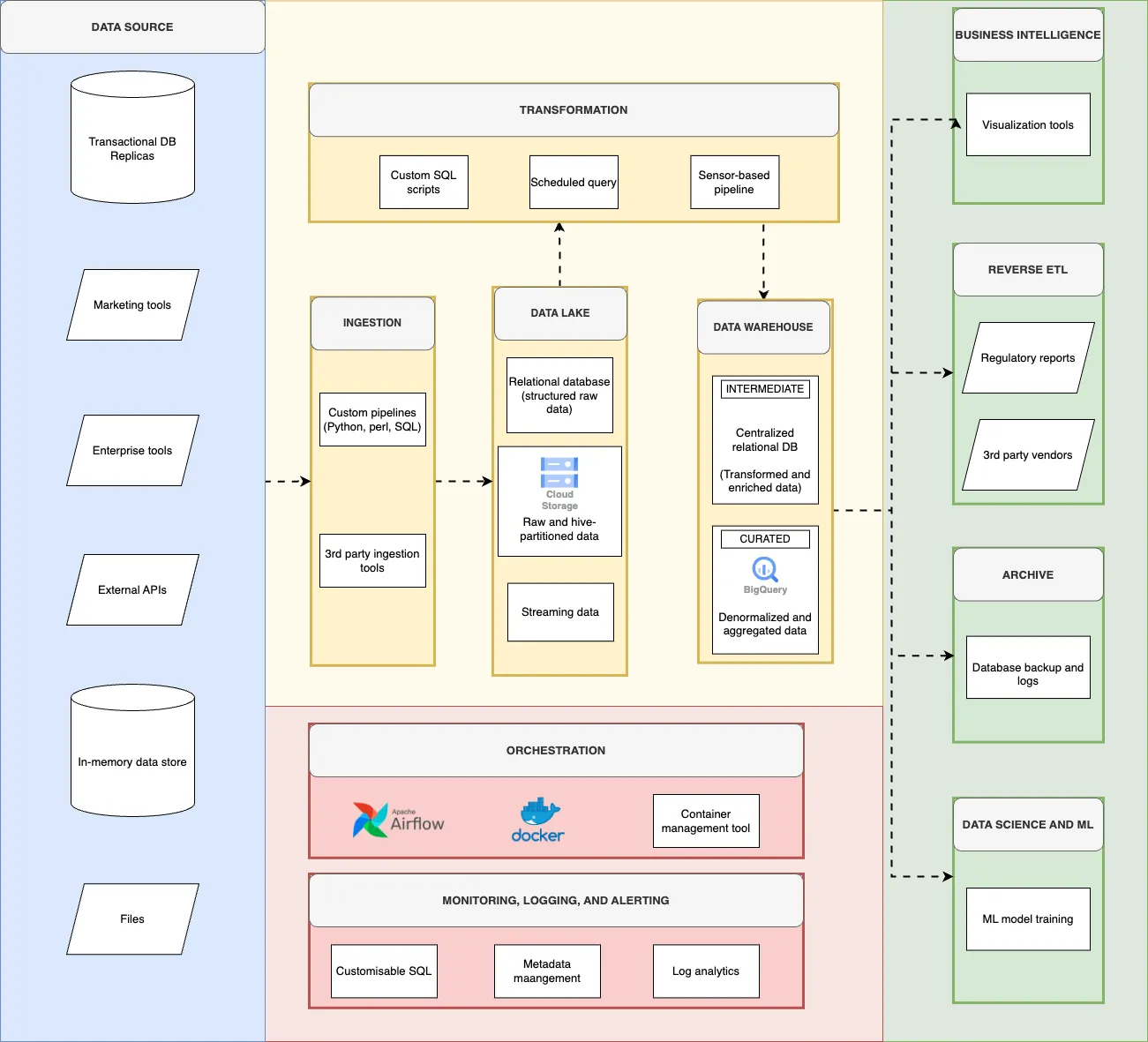
The foundation of our data platform: Key data sources
Deriv's data ecosystem draws from a diverse array of sources, much like a city's various infrastructure networks. The data engineering team expertly manages the collection and integration of data from relational databases, APIs, and external files, ensuring a comprehensive and reliable data foundation.
Workflow orchestration: Leveraging airflow DAGs
To automate and streamline the data pipelines, our data engineering team utilises Airflow, a powerful workflow orchestration tool. Think of it as a traffic control system for our data highways. Airflow’s Directed Acyclic Graphs (DAGs) help schedule and manage the execution of various data processing tasks, ensuring the timely delivery of data to the different teams. Just as traffic patterns vary throughout the day, some of our data tables update daily with product metrics, while others capture per-minute user login activities and even real-time trade data.
Relational database management system
To minimise disruptions to the main business operations, the data engineering team leverages read replicas and configuration management tools when working with relational databases. This approach, illustrated in Figure 2, allows them to maintain data integrity and reliability while seamlessly integrating the data into the data warehouse. It’s akin to having a backup power grid that ensures continuous operations, even during maintenance or upgrades.
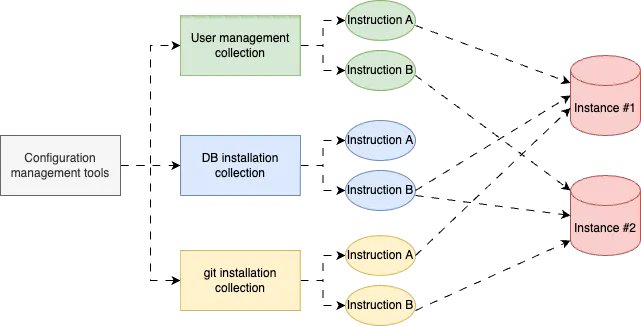
How to populate the data warehouse
Deriv uses two data warehouse systems: a centralised relational database and Google BigQuery. Before loading data into BigQuery, the data is typically processed in the centralised relational database, where transformations and aggregations are applied using SQL functions. This is like refining raw materials before sending them to a factory for further processing.
In BigQuery, the team generates data marts from scheduled queries, which feed visualisation tools, regulatory reports, and machine learning models. These data marts can be thought of as specialised warehouses within the larger facility, each catering to specific needs.
Why we still need relational database
The centralised relational database acts as an intermediary between data sources and BigQuery. By residing on the same network as the transactional database replicas, the team can conveniently access the data. The data is processed in batches, refined, and moved to corresponding schemas. It’s similar to a staging area where goods are sorted and prepared for shipment to their final destinations.
To achieve near real-time ingestion into the centralised data warehouse, the team uses a custom remote-data-access module to query data directly from the read replicas without source-side scripting. This allows for faster data updates, similar to express delivery services that bypass traditional shipping routes.
Google BigQuery: Our scalable cloud data warehouse
The next layer of the data warehouse is BigQuery. We chose it for the following reasons:
- Serverless architecture: We don’t need to worry about resource management when executing queries. Its columnar storage is optimised for analytical workloads, efficiently scanning sparse column subsets. It’s like having a self-driving car that adapts to traffic conditions and optimises its route for maximum efficiency.
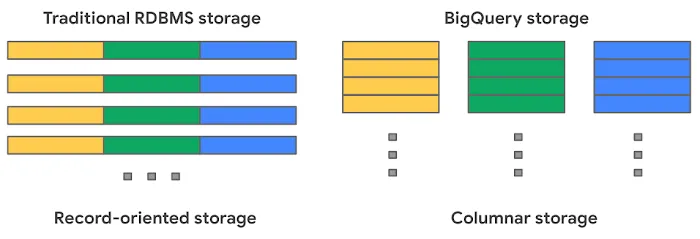
- Easy permission management: We ensure each team only accesses relevant data by using a built-in access management service. This is similar to having secure access control systems in a building, granting entry only to authorised personnel.
Data shipping: Multi-method approaches for BigQuery loading
We use various methods to load data into BigQuery:
- Batch processing: Pipeline loads batches of staged files from cloud storage into BigQuery tables for a specific scheduled interval. This is like scheduled cargo deliveries that arrive at set times.
- Stream processing: We use a streaming API to process data in near real-time. This is like a live news feed that constantly updates with the latest information.
- Event-based trigger and external tables: Sensor-based pipeline processes new files arriving in cloud storage buckets, applying transformations and kicking off relevant pipeline logics. This is like a motion sensor that triggers an alarm when something new enters its field of view.
- BigQuery external tables: Access data from files in external storage. This is like accessing files from a remote server.
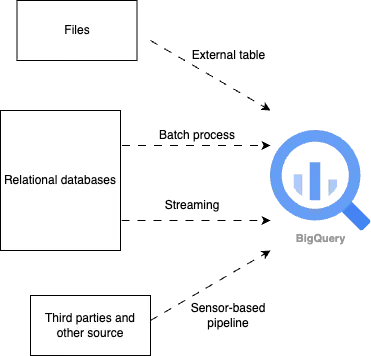
Maximising value: Our dual BigQuery pricing model strategy
To optimise costs, Deriv utilises two BigQuery pricing models: On-Demand, which charges per query based on scanned bytes, and Capacity, which utilises reserved compute slots.
The On-Demand model is used for data ingestion pipelines and scheduled queries, while the Capacity model is used for ad-hoc queries, dashboards, and reports.
This separation ensures that ad-hoc reports do not interfere with the primary data pipeline execution and allows for better control of query costs. It's like having both a pay-as-you-go plan and a monthly subscription for your phone, depending on your usage patterns.
Data monitoring tools: Our approach to logging, alerting, and monitoring
Think of a health monitoring system that keeps track of your vital signs and alerts you to any potential problems. In a similar manner, we monitor the pipeline for issues such as server failures, data anomalies, or bugs, ensuring the reliability of our data and system.

Here are a few ways we monitor our system:
- Customisable SQL dashboards to look out for data anomalies in business metrics. These dashboards are like the gauges on a car's dashboard, providing real-time information on the system's performance.
- Log analytics to monitor instances and alert for any failed pipelines. This is similar to having a black box that records everything that happens in the system, allowing us to investigate any incidents.
- Metadata management to keep track of data changes within our system. This is like having a version control system that tracks changes to documents over time.
We integrate with email and Slack providers to receive notifications from our alerting tools so we can be immediately informed of any critical issues and take swift action.
Data quality: Maintaining data integrity across systems
Maintaining data quality is crucial for Deriv. The team has created a custom data quality pipeline to check for duplicates and ensure consistent data counts across data warehouses. In the centralised database, we use primary and unique key constraints, while for BigQuery, which lacks enforced primary keys, we created a metadata table defining primary key columns. Additionally, we audit data volumes across layers, ensuring that the record counts ingested into BigQuery match those in the first relational database layer for all tables on a daily basis.
Docker containerisation: Deploying key applications in containers
We deploy applications in a Docker swarm using container management software. This allows us to manage container deployments, networks, volumes, credentials, and scaling across instances. Updating a docker service’s version only requires editing the docker-compose.yml file and redeployment, with easy rollbacks if needed. It's like having pre-fabricated building blocks that can be easily assembled and disassembled, allowing for flexible and efficient construction.
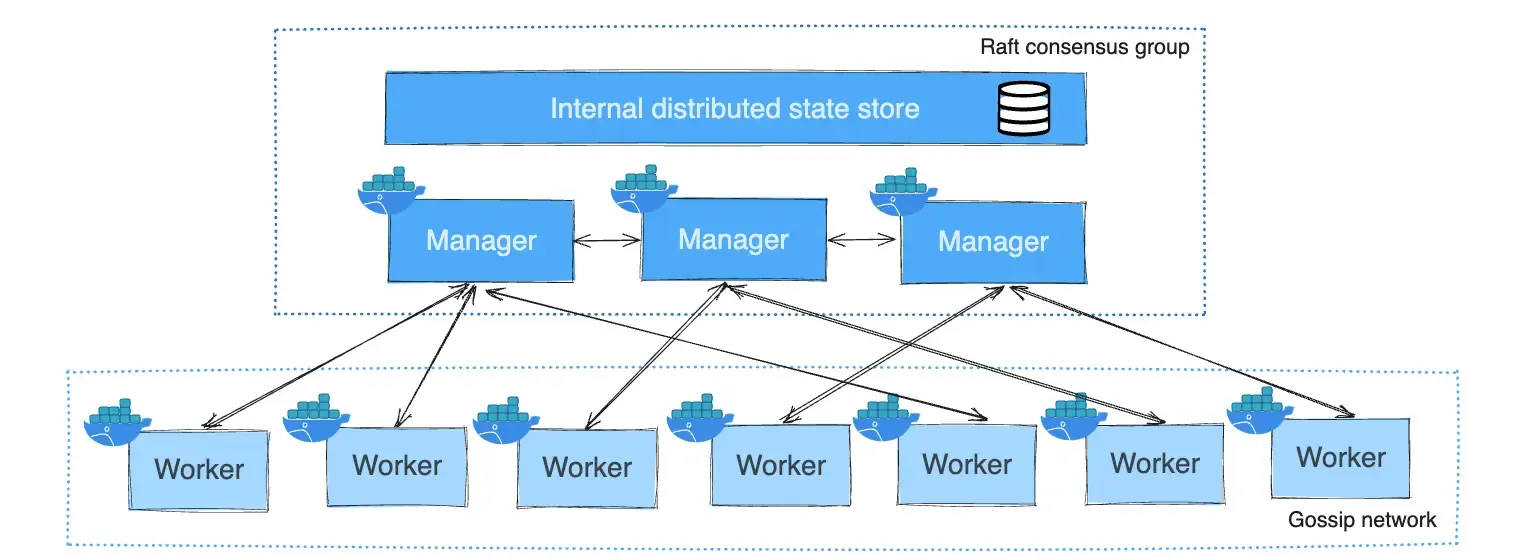
Security best practices: Ensuring secure data management
We maintain distinct staging and production environments, each with unique networking configurations. The staging environment enables us to test changes safely before deploying them to production, thereby reducing risk. Additionally, we implement two-factor authentication for accessing our services, providing an extra layer of security.
We regularly update our codebase and infrastructure in accordance with security best practices. A designated team audits for vulnerabilities, updating tools, rotating credentials, and decommissioning legacy systems. Data access adheres to the principle of least privilege within each department, with additional contexts, such as PII, requiring specific approval.
Data Engineering's role in shaping Deriv's data-driven future
Our Data Engineering team focuses on building a data infrastructure that integrates various data sources into the data warehouse. Logging, monitoring, and security best practices ensure data quality and reliability.
While the details in this article may be subject to change, our fundamental commitment to facilitating fast and precise decision-making remains unchanged. We value your input and encourage you to share your thoughts on our strategy.
About the author
Fauzan Ragitya is a Data Engineer at Deriv with a passion for lifelong learning. He’s constantly expanding his expertise in data analytics and data infrastructure.











.webp)



















%2520(1).png)
.webp)
.jpeg)



%2520(1).webp)
.webp)



.webp)













.webp)





